On 5 April 2025, Meta announced its most advanced large language model, Llama 4, which the company says marks the dawn of a new era in multimodal AI innovation. The new model family debuted with two main variants: Llama 4 Scout and Llama 4 Maverick, capable of processing and integrating text, images, videos, and audio, while also converting content across these formats.
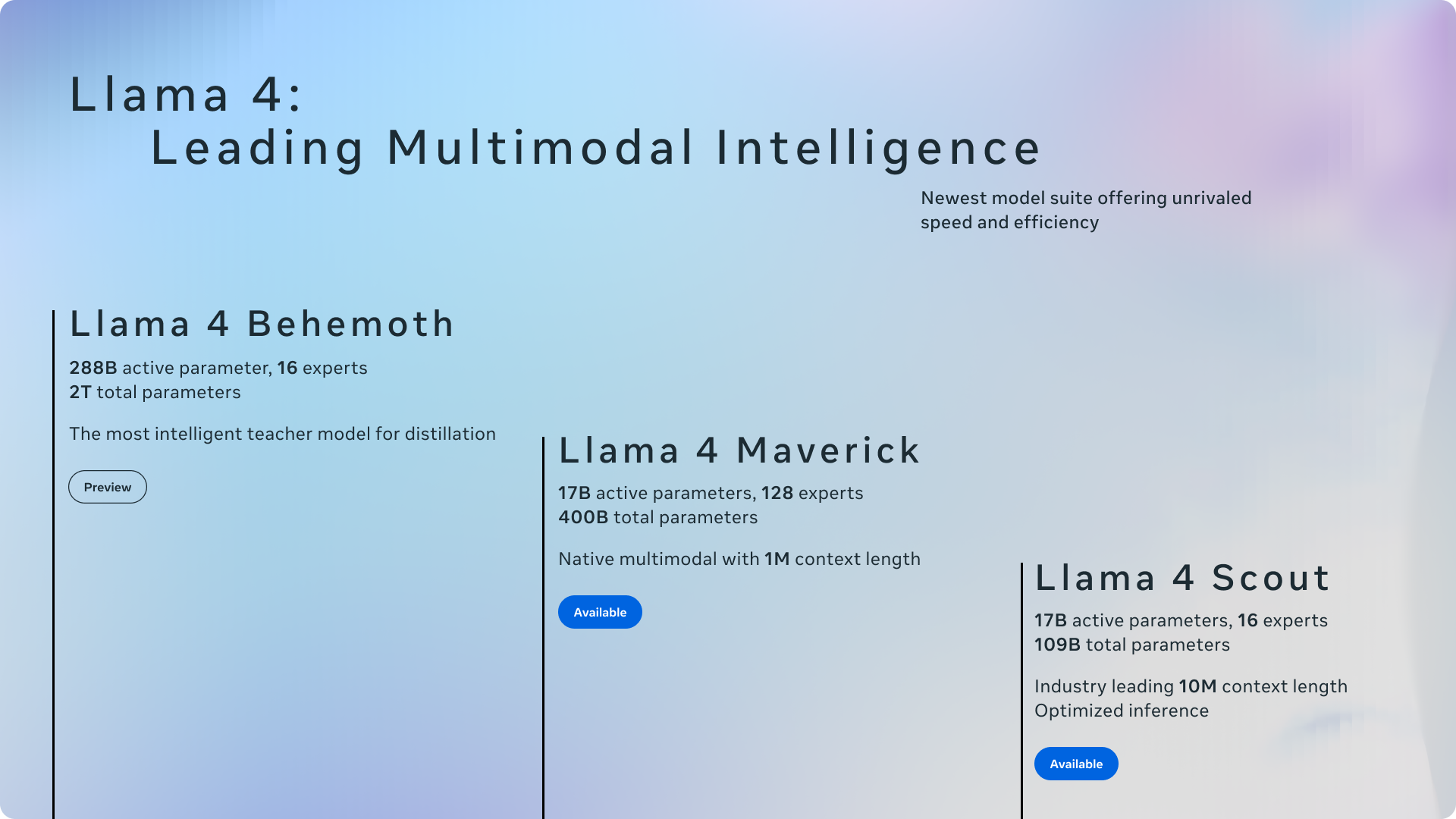
Meta’s new models employ a mixture-of-experts (MoE) architecture, significantly enhancing efficiency. As stated in Meta’s release, MoE models activate only a subset of parameters for a single token, making them computationally more efficient during training and inference, and delivering better quality for a given training FLOP budget compared to previous models. Llama 4 Maverick has 17 billion active and 400 billion total parameters, while Llama 4 Scout features 17 billion active and 109 billion total parameters.
The company also teased a third, even more powerful model: Llama 4 Behemoth, boasting 288 billion active parameters and nearly two trillion total parameters. The significance of the Llama 4 models is heightened by their open-source nature, allowing developers to download and use them freely. The Scout model is particularly notable for its 10 million token context window, a substantial leap from Llama 3’s 128,000-token capacity. Meta claims Llama 4 Maverick outperforms similar models, competing with the much larger DeepSeek v3.1 in coding and logical reasoning. However, analysts have pointed out that Meta’s published performance data may be somewhat misleading, as the tested model version might differ from the publicly available one. Nonetheless, the Llama 4 models represent a significant advancement in artificial intelligence.
Sources:
1.
2.
3.