
While generative AI can assist in many parts of the research process, writing a literature review remains a task that requires a careful, hybrid approach, combining traditional research methods with AI-driven synthesis. As established in previous sections, both specialised search tools and general-purpose models have limitations—either in the scope of their databases or in their tendency to hallucinate sources. Therefore, a robust and reliable workflow, as illustrated in the Figure below, involves the researcher taking on the critical role of information gathering before leveraging the generative AI models for textual synthesis. This process ensures that the foundation of the literature review is built upon a complete and verified set of sources curated by the researcher.
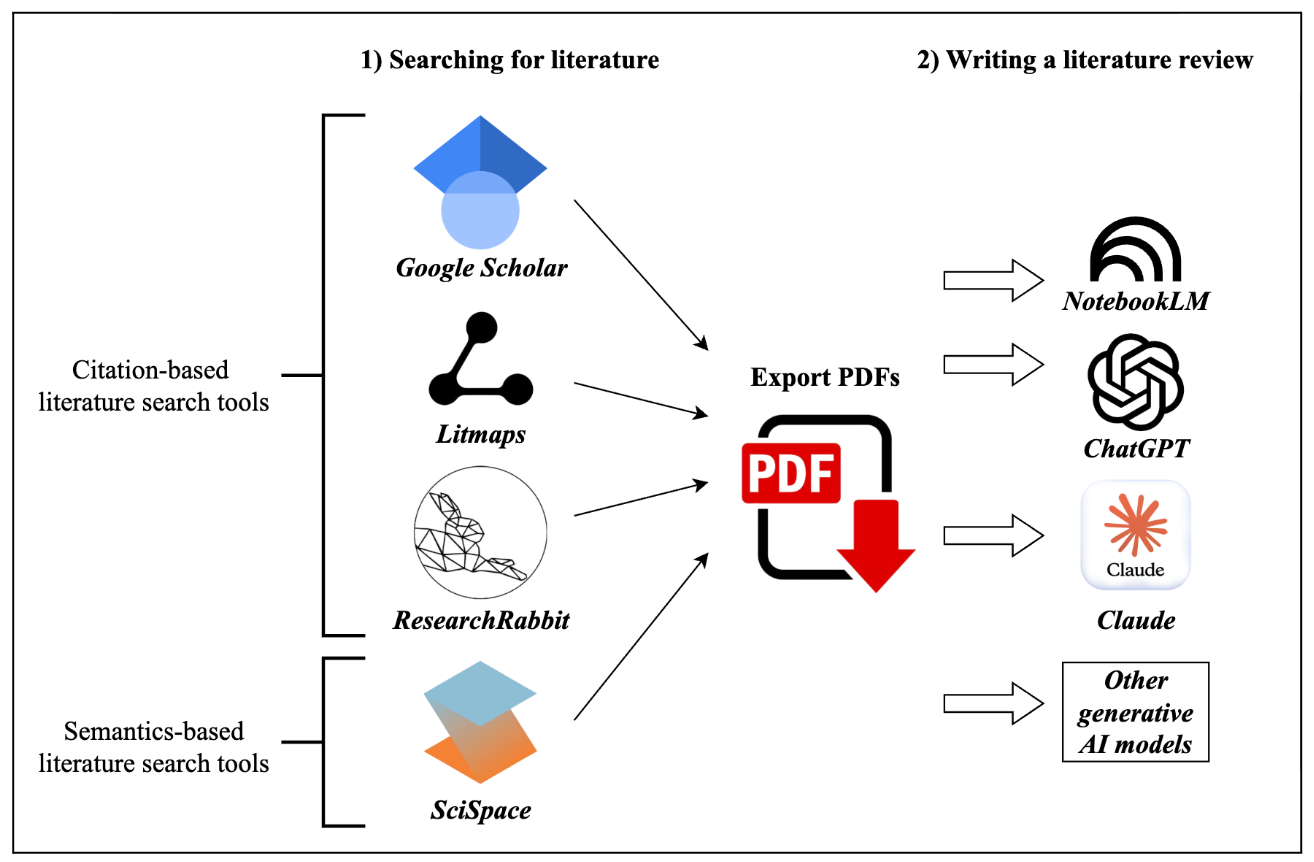
The initial phase of this workflow involves two stages: identifying potential sources and then curating the definitive collection. Researchers can leverage the AI-powered search tools discussed in the previous section (e.g., Litmaps, ResearchRabbit) to rapidly identify a broad list of potentially relevant papers. However, the second stage, curation, remains a critical and non-negotiable human task. The researcher must manually gather the full-text PDF versions of the selected papers. This step is essential because a link or citation provided by a model does not guarantee that the AI can or will access the complete document. It may only have access to the abstract or, in some cases, the link may be incorrect. To write a literature review of appropriate scholarly depth, the full content of each article is required. By manually curating the definitive set of PDF sources, the researcher ensures that the foundation of the review is complete and verified before proceeding to the AI-assisted synthesis phase.
Once the curated collection of source PDFs is complete, the researcher can leverage a generative AI tool for the synthesis phase. The collected PDFs are uploaded directly to the model, in batches if necessary, creating a controlled information environment based on a researcher-defined corpus. At this stage, a detailed and specific prompt becomes the primary research instrument, guiding the model to perform a structured analysis based only on the provided texts. The primary advantage of this approach is that it significantly mitigates the risk of source hallucination (i.e., inventing non-existent papers). However, this does not eliminate all potential errors. The model may still misinterpret nuanced arguments or oversimplify complex theories. Crucially, it can also hallucinate facts or claims about the provided documents, misrepresenting their content even when the correct source is available. Therefore, the researcher's role shifts from that of a primary writer to a critical editor, responsible for rigorously validating the AI's interpretation and synthesis against the original source texts.





