
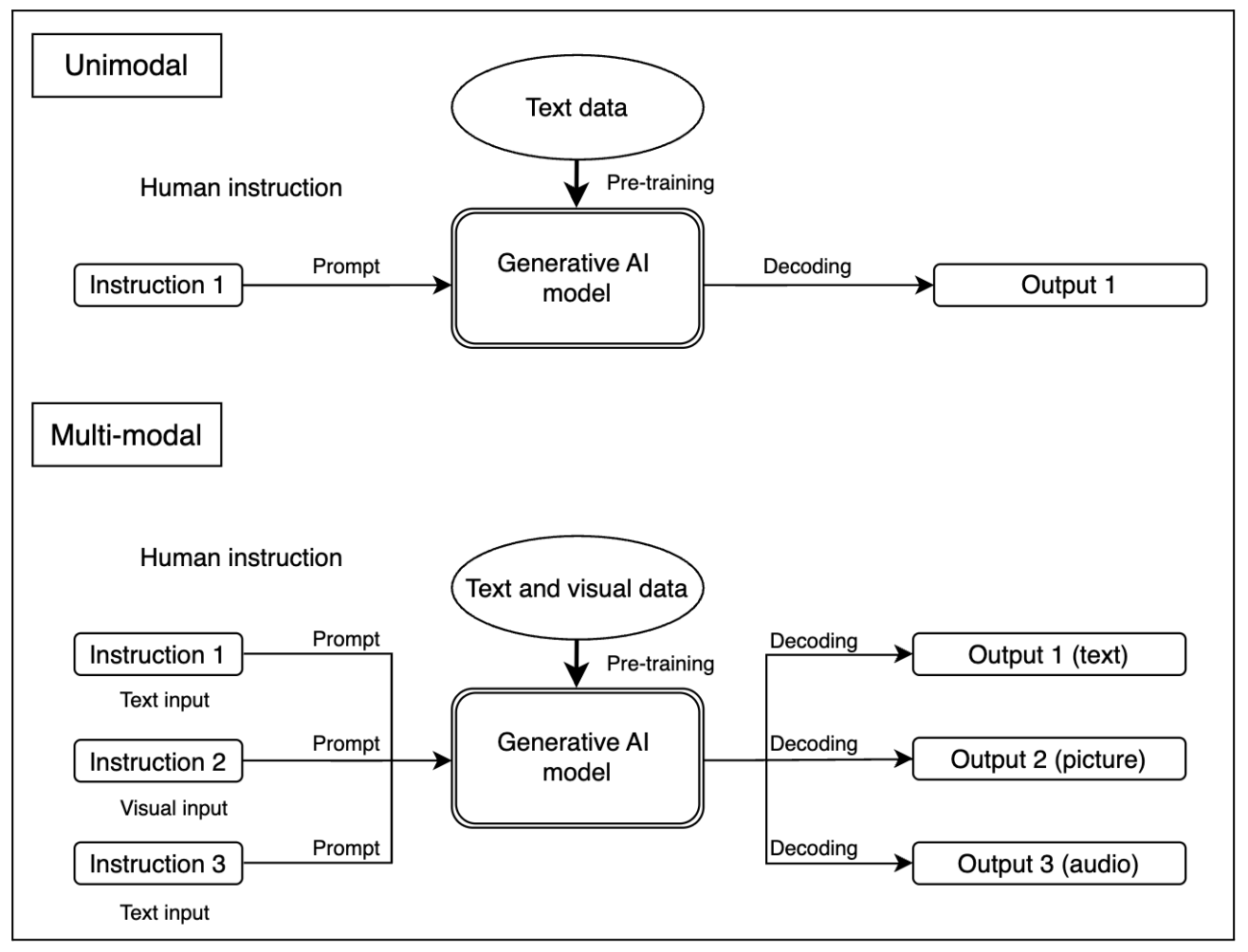
Beyond their underlying architectures, another crucial way to classify generative systems is by the type of data—or modality—they process and generate. Previously, such models were typically limited to a single modality (unimodal), meaning they were designed to process and generate only one type of content. A prominent example is OpenAI’s GPT-3, which operated exclusively on textual inputs and generated text-based outputs. However, recent advancements have given rise to multimodal models, capable of processing and generating multiple types of content across different formats simultaneously (Banh & Strobel 2023, 7). One such example is the multimodal version of OpenAI’s GPT-4, which can interpret both textual and visual data and generate outputs by combining these modalities. The functioning of unimodal and multimodal models is illustrated in the figure below.
Fig. 4. Functioning of Unimodal and Multimodal Generative AI Models
A distinct but related category involves cross-modal models, which specialise in transforming data across different modalities (Zhang et al. 2021). These models enable, for example, the generation of images from text—as demonstrated by DALL·E—or the generation of textual descriptions from images, which is one of the key capabilities of the CLIP model. Such models play a particularly important role in areas such as Visual Question Answering, text-to-image generation, and multimodal information retrieval.
References:
1. Banh, Leonardo, and Gero Strobel. 2023. ‘Generative Artificial Intelligence’. Electronic Markets 33 (1): 63. doi:10.1007/s12525-023-00680-1 – ^ Back
2. Hariri, Walid. 2023. ‘Unlocking the Potential of ChatGPT: A Comprehensive Exploration of Its Applications, Advantages, Limitations, and Future Directions in Natural Language Processing’. arXiv. doi:10.48550/ARXIV.2304.02017 – ^ Back
3. Zhang, Han, Jing Yu Koh, Jason Baldridge, Honglak Lee, and Yinfei Yang. 2021. ‘Cross-Modal Contrastive Learning for Text-to-Image Generation’. arXiv. doi:10.48550/ARXIV.2101.04702 – ^ Back





