
The attention mechanism has fundamentally reshaped natural language processing (NLP), enabling models to capture complex linguistic relationships with unprecedented accuracy. Introduced prominently in Vaswani et al. (2017), attention allows models to focus on relevant parts of input sequences, enhancing performance in tasks like machine translation and sentiment analysis. This essay examines the theoretical foundations, mechanics, and impact of attention mechanisms, arguing that their ability to model context and dependencies is central to understanding linguistic relationships. It draws on key scholarly sources, including foundational and recent works, and addresses limitations and future directions.
Attention mechanisms emerged to overcome the limitations of recurrent neural networks (RNNs), which struggle with long-range dependencies due to vanishing gradients (Hochreiter & Schmidhuber 1997). RNNs, as described by Elman (1990), process sequences sequentially, making it difficult to capture distant syntactic or semantic relationships in complex sentences. Attention addresses this by dynamically weighting input elements based on their relevance. The concept was formalised by Bahdanau et al. (2014), who introduced additive attention for neural machine translation. This mechanism aligns source and target sequences by computing a weighted sum of input representations, enabling the model to focus on contextually significant words regardless of their position.
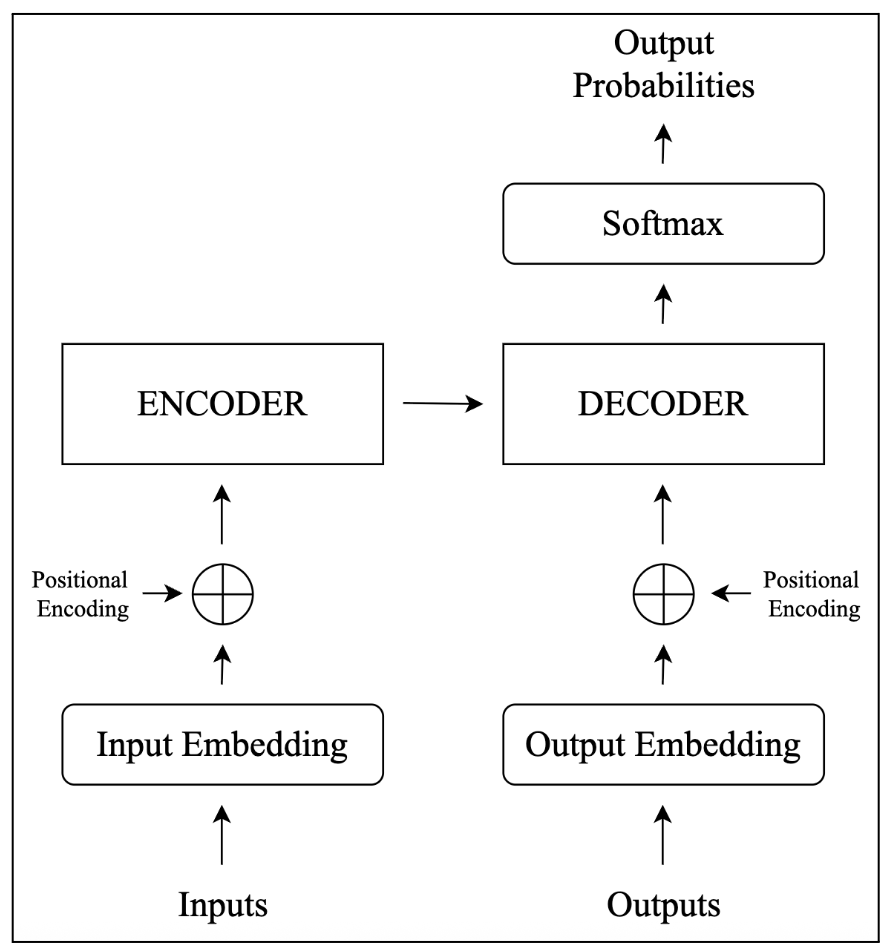
The Transformer model, proposed by Vaswani et al. (2017), marked a turning point in NLP by relying entirely on attention, eliminating recurrent architectures. As shown in the simplified illustration in Figure 1, the model is fundamentally based on an encoder-decoder architecture. Its core component, scaled dot-product attention, computes similarity scores between query, key, and value vectors, scaled to stabilise gradients. Multi-head attention allows the model to capture diverse linguistic relationships simultaneously, such as syntactic dependencies and semantic associations. For example, in the sentence “The cat, which was sitting on the mat, was purring”, the Transformer’s self-attention links “cat” to “purring” despite the intervening clause, demonstrating its ability to handle long-range dependencies. This capability, combined with parallel processing, makes the Transformer highly parallelizable and thus significantly faster to train than RNNs, as evidenced by its superior performance in machine translation (Vaswani et al., 2017). The Transformer’s architecture underpins models like BERT (Devlin et al. 2019), which further refine linguistic relationship modelling through contextualised embeddings.
Fig. 1. Simplified illustration of the transformer model encoder-decoder architecture
Attention mechanisms excel at capturing semantic and syntactic relationships critical for tasks like coreference resolution and question answering. For instance, Lee et al. (2017) used attention to improve entity tracking across sentences, linking pronouns to their antecedents. Similarly, BERT’s self-attention enables it to learn contextualised representations that capture polysemy and context-dependent meanings, significantly advancing tasks requiring deep linguistic understanding (Devlin et al. 2019). Attention also enhances interpretability by revealing which input elements the model prioritises. Visualising attention weights in translation tasks shows how the model aligns source and target words, providing insights into its understanding of linguistic relationships (Bahdanau et al. 2014). This interpretability is valuable for refining models and ensuring their reliability in applications like automated summarisation.
The attention mechanism has revolutionised NLP by enabling models to capture intricate linguistic relationships through context-aware weighting. Its theoretical alignment with human cognition, operational efficiency, and interpretability makes it indispensable for modern language models. While limitations like computational complexity and interpretability challenges persist, ongoing innovations promise to expand its capabilities. The attention mechanism remains the cornerstone of understanding linguistic relationships, driving progress towards more sophisticated NLP systems.
References:
1. Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2014. ‘Neural Machine Translation by Jointly Learning to Align and Translate’. arXiv preprint arXiv:1409.0473. ^ Back
2. Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. ‘BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding’. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 4171–86. ^ Back
3. Elman, J. L. (1990). ‘Finding Structure in Time’. Cognitive Science, 14(2), 179–211. ^ Back
4. Hochreiter, S., & Schmidhuber, J. (1997). ‘Long Short-Term Memory’. Neural Computation, 9(8), 1735–1780. ^ Back
5. Lee, Kenton & He, Luheng & Lewis, Mike & Zettlemoyer, Luke. End-to-end neural coreference resolution. arXiv preprint arXiv:1707.07045, 2017. ^ Back
6. Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. ‘Attention Is All You Need’. arXiv. doi:10.48550/ARXIV.1706.03762 – ^ Back





