
Officially released on June 26, 2025, Gemma 3n includes significant developments specifically targeting on-device AI operation. The multimodal model natively supports image, audio, video, and text inputs and is available in two sizes: E2B (5 billion parameters) and E4B (8 billion parameters), operating with just 2GB and 3GB of memory respectively.
At the core of Gemma 3n are several pioneering technologies, including the MatFormer (Matryoshka Transformer) architecture, which allows developers to extract smaller sub-models or dynamically adjust model size. The Per-Layer Embeddings (PLE) technique reduces required parameters by 46%, while KV Cache Sharing delivers a 2x improvement in prefill performance compared to Gemma 3 4B. The new MobileNet-V5 vision system can process up to 60 frames per second on a Google Pixel device, representing a 13x speedup with quantization. The integrated audio analyzer based on the Universal Speech Model enables on-device speech recognition and translation, currently limited to 30-second audio clips.
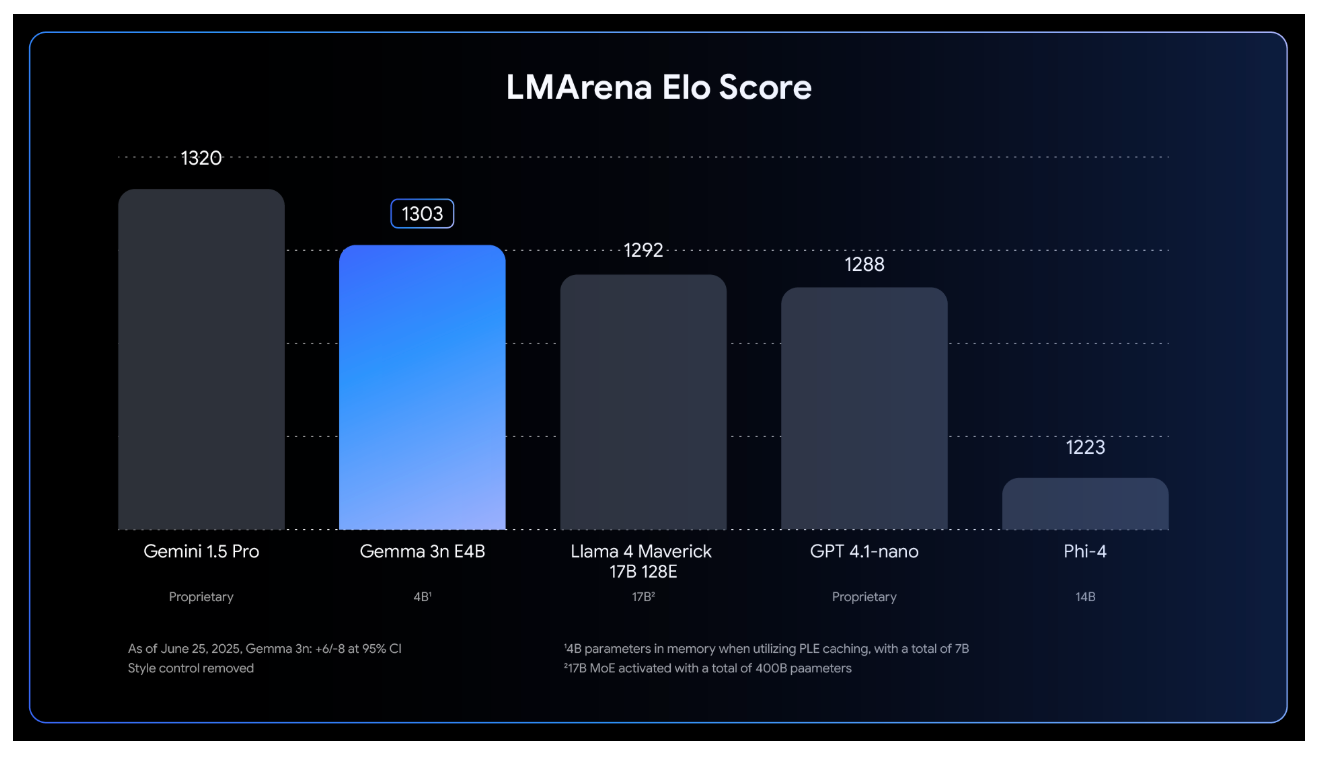
Gemma 3n achieved an LMArena score exceeding 1300, the first such result for a model under 10 billion parameters. The model supports 140 languages for text and multimodal understanding of 35 languages. The original Gemma model family has already reached 160 million downloads, and Google actively supports the ecosystem for developers, including Hugging Face Transformers, llama.cpp, Ollama, and other tools. Google also launched the Gemma 3n Impact Challenge, offering $150,000 in prizes for real-world applications built on the platform, further incentivising the developer community.
Sources:
1.

2.

3.






